Streamlining Data and Machine Learning Workflows with DataOps and MLOps
Week 1, Day 5: DataOps and MLOps
Welcome to the final day of Week 1: Data Engineering Fundamentals in our Data Engineering, Analytics, and Emerging Trends series! Today, we’re diving into DataOps and MLOps—two critical practices for managing data and machine learning workflows efficiently. Whether you’re a data engineer, data scientist, or ML practitioner, these methodologies will help you streamline processes, improve collaboration, and deliver faster results. Let’s get started!
Why DataOps and MLOps Matter
As data and machine learning projects grow in complexity, traditional workflows often become bottlenecks. DataOps and MLOps address these challenges by:
Improving Collaboration: Break down silos between teams.
Automating Workflows: Reduce manual effort and errors.
Ensuring Reproducibility: Track changes and maintain version control.
Accelerating Delivery: Deploy models and insights faster.
Topics Covered
1. What is DataOps?
DataOps is a set of practices that improve the speed, quality, and reliability of data analytics by applying DevOps principles to data workflows.
Key Principles
Automation: Automate data pipelines, testing, and deployment.
Collaboration: Foster teamwork between data engineers, analysts, and scientists.
Monitoring: Continuously monitor data quality and pipeline performance.
Iteration: Iterate quickly based on feedback and changing requirements.
Real-World Example:
A retail company uses DataOps to automate its ETL pipelines, ensuring daily sales data is clean, reliable, and ready for analysis.
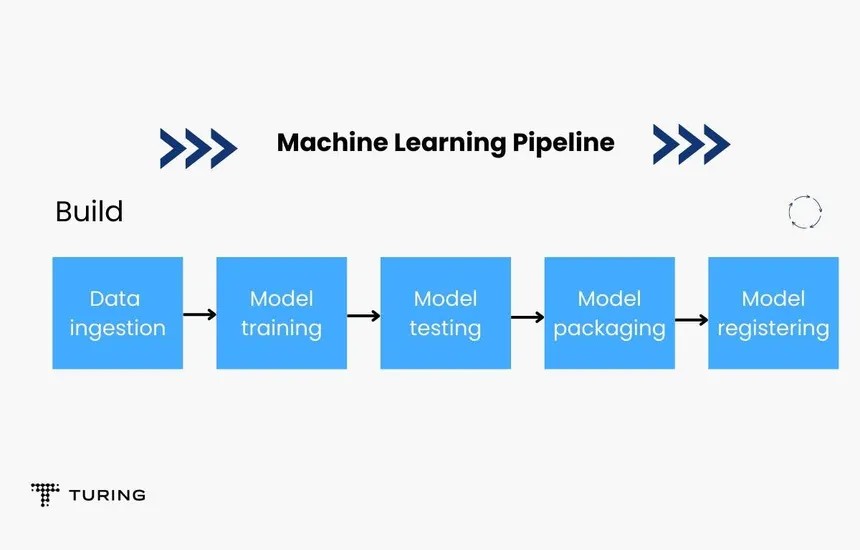
2. What is MLOps?
MLOps (Machine Learning Operations) extends DevOps principles to machine learning workflows, ensuring seamless collaboration between data scientists and engineers.
Key Principles
Version Control: Track changes to data, code, and models.
Continuous Integration/Continuous Deployment (CI/CD): Automate model training and deployment.
Monitoring: Track model performance and retrain as needed.
Reproducibility: Ensure experiments can be replicated.
Real-World Example:
A healthcare company uses MLOps to deploy and monitor a predictive model that forecasts patient readmission rates.
3. Tools for DataOps and MLOps
MLflow
MLflow is an open-source platform for managing the end-to-end machine learning lifecycle.
Key Features:
Experiment Tracking: Log parameters, metrics, and artifacts.
Model Registry: Store and version models.
Project Packaging: Package code for reproducibility.
Example:
Track an experiment:
import mlflow
mlflow.start_run()
mlflow.log_param("learning_rate", 0.01)
mlflow.log_metric("accuracy", 0.95)
mlflow.end_run()
Register a model:
mlflow.sklearn.log_model(model, "model")
Kubeflow
Kubeflow is a platform for deploying and managing machine learning workflows on Kubernetes.
Key Features:
Pipeline Orchestration: Define and run ML pipelines.
Scalability: Leverage Kubernetes for distributed computing.
Integration: Works with TensorFlow, PyTorch, and other frameworks.
Example:
Define a pipeline:
from kfp import dsl
@dsl.pipeline(name="ML Pipeline")
def ml_pipeline():
preprocess_op = dsl.ContainerOp(name="preprocess", image="preprocess-image")
train_op = dsl.ContainerOp(name="train", image="train-image")
train_op.after(preprocess_op)
Deploy the pipeline on Kubernetes.
4. Best Practices for DataOps and MLOps
Automate Everything: Use CI/CD pipelines for data and ML workflows.
Monitor Continuously: Track data quality, pipeline performance, and model accuracy.
Collaborate Effectively: Use tools like Git, Jira, and Slack to improve teamwork.
Document Thoroughly: Maintain clear documentation for pipelines, models, and processes.
Pro Tip: Build Your First Real-Time Pipeline with Kafka and Spark Streaming
Combine DataOps and MLOps principles to build a real-time data pipeline:
Use Apache Kafka to ingest streaming data.
Process the data with Spark Streaming.
Store the results in a data warehouse (e.g., Snowflake).
Use dbt to transform the data for analysis.
Practice Tasks
Task 1: Track an ML Experiment with MLflow
Install MLflow:
pip install mlflow
Log parameters, metrics, and artifacts for a simple ML model.
Task 2: Set Up a Kubeflow Pipeline
Install Kubeflow on a Kubernetes cluster.
Define and deploy a simple ML pipeline.
Task 3: Automate a Data Pipeline
Use Apache Airflow or Prefect to automate an ETL pipeline.
Monitor the pipeline for errors and performance.
Key Takeaways
DataOps: Streamlines data workflows with automation, collaboration, and monitoring.
MLOps: Manages the machine learning lifecycle for faster, more reliable deployments.
Tools: Use MLflow for experiment tracking and Kubeflow for pipeline orchestration.
Best Practices: Automate, monitor, collaborate, and document.