From Messy to Meaningful: Cleaning and Preparing Data for Analysis
Welcome to Day 2 of Data Engineering, Analytics, and Emerging Trends!
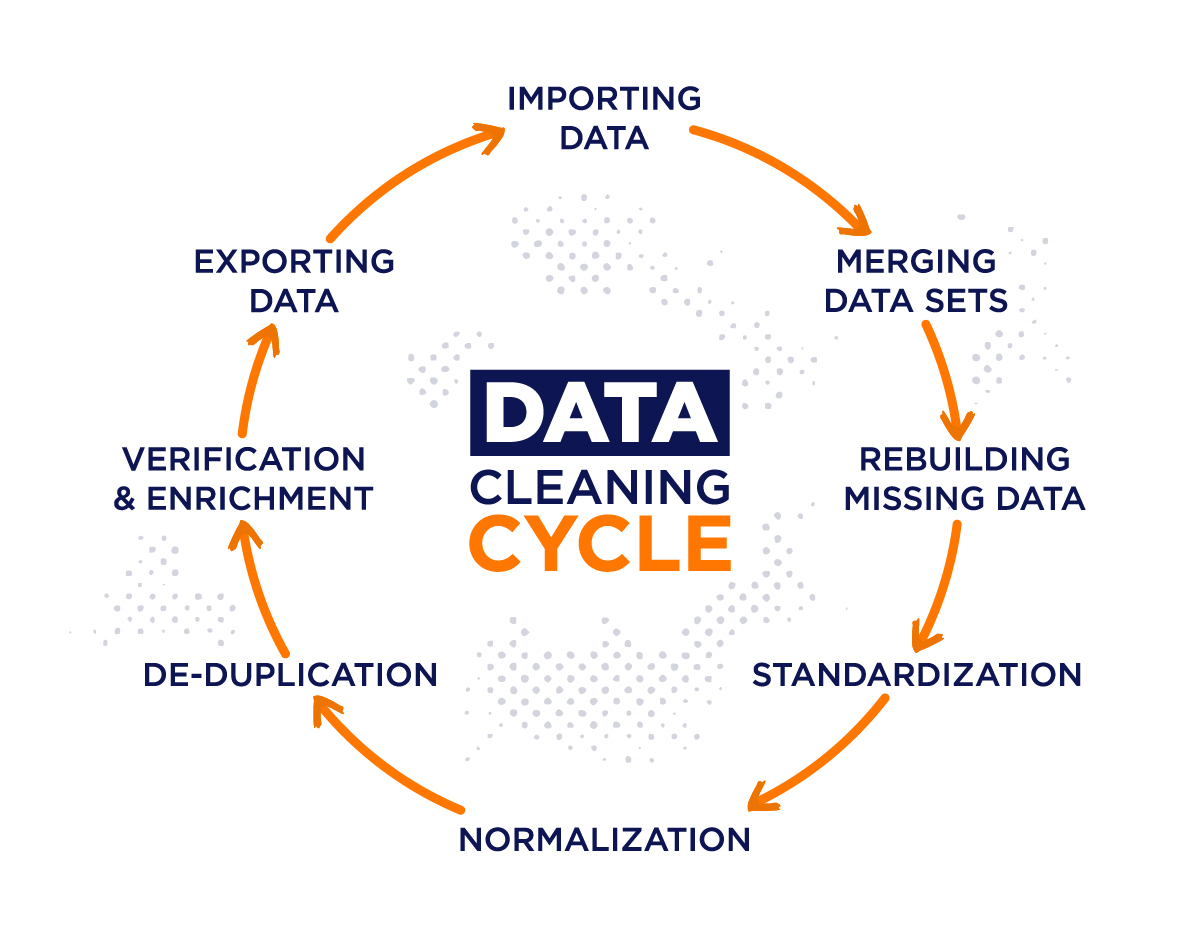
Yesterday, we explored how to build data pipelines. Today, we're diving into one of the most critical steps in the data engineering process: data transformation and cleaning. Clean, well-prepared data is the foundation of accurate analysis and reliable insights. Let's roll up our sleeves and turn messy data into something meaningful!
Why Data Transformation and Cleaning Matter
Raw data is often incomplete, inconsistent, or riddled with errors. Without proper cleaning and transformation, your analysis could lead to incorrect conclusions and flawed decision-making. Data transformation ensures that:
- Data is Consistent: Standardized formats, units, and naming conventions.
- Errors are Fixed: Missing values, duplicates, and outliers are handled appropriately.
- Data is Validated: Ensuring data quality and adherence to defined rules.
- Data is Ready for Analysis: Structured, optimized for queries, and in a format suitable for your chosen tools.
Think of it this way: you wouldn't build a house on a shaky foundation, would you? Clean data is your strong foundation for data-driven success!
Topics Covered
What is Data Transformation?
Data transformation involves converting raw data into a format that's suitable for analysis and reporting. It's a multi-step process that can include:
- Cleaning: Fixing errors, inconsistencies, and inaccuracies.
- Normalization: Scaling data to a standard range (e.g., 0 to 1).
- Aggregation: Summarizing data (e.g., daily sales totals).
- Enrichment: Adding new data from external sources.
- Data Profiling: Understanding its structure and relationships.
- Data Validation: Defining and enforcing rules to ensure data quality.
Real-World Example:
A retail company cleans, transforms, and validates raw sales data to calculate monthly revenue by product category, identify top-selling products, and predict future sales trends.
Tools for Data Transformation
- Pandas (Python): Ideal for smaller datasets and exploratory work.
- PySpark (Python): Designed for handling large-scale datasets.
- dbt (Data Build Tool): A SQL-based tool for transforming data within a data warehouse.
Pandas Example: Cleaning a Dataset with Missing Values
import pandas as pd
try:
df = pd.read_csv('sales.csv')
except FileNotFoundError:
print("Error: sales.csv not found. Please check the file path.")
exit()
print("Original DataFrame Info:")
print(df.info())
df['Revenue'].fillna(df['Revenue'].mean(), inplace=True)
df['OrderDate'] = pd.to_datetime(df['OrderDate'], errors='coerce')
df.dropna(subset=['OrderDate'], inplace=True)
df.drop_duplicates(inplace=True)
df.to_csv('cleaned_sales.csv', index=False)
print("\nCleaned DataFrame Info:")
print(df.info())PySpark Example: Aggregating Sales Data by Region
from pyspark.sql import SparkSession
from pyspark.sql.functions import sum, col
spark = SparkSession.builder.appName("DataCleaning").getOrCreate()
df = spark.read.csv('sales.csv', header=True, inferSchema=True)
df_agg = df.groupBy('Region').agg(sum(col('Revenue')).alias('TotalRevenue'))
df_agg.write.csv('sales_by_region.csv', mode="overwrite")
spark.stop()dbt Example: Creating a Cleaned Dataset in Snowflake
SELECT
OrderID,
CustomerID,
OrderDate,
SUM(Revenue) AS TotalRevenue
FROM {{ source('raw_data', 'raw_sales') }}
GROUP BY OrderID, CustomerID, OrderDate;Common Data Cleaning Tasks
- Handling Missing Values: Fill, impute, or remove.
- Removing Duplicates: Avoid skewing analysis.
- Fixing Data Types: Ensure correct formats.
- Handling Outliers: Detect and process outliers effectively.
Pro Tip: Automate Data Pipelines with Apache Airflow
Use Apache Airflow to automate data transformation workflows.
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
def clean_data():
print("Running data cleaning task...")
with DAG(
dag_id='data_cleaning_pipeline',
start_date=datetime(2023, 1, 1),
schedule_interval='@daily',
catchup=False
) as dag:
clean_task = PythonOperator(
task_id='clean_data_task',
python_callable=clean_data
)Practice Tasks
- Task 1: Clean a Dataset
- Download a messy dataset (e.g., from Kaggle or UCI Machine Learning Repository).
- Use Pandas or PySpark to clean the data (handle missing values, remove duplicates, fix data types, handle outliers).
- Save the cleaned dataset.
- Task 2: Transform Data with dbt
- Set up dbt and connect it to your data warehouse (e.g., Snowflake, BigQuery).
- Write a SQL model to aggregate sales data by product category and calculate key metrics.
- Task 3: Automate with Airflow
- Create an Airflow DAG to clean and transform data from a CSV file.
- Schedule the DAG to run daily.
Key Takeaways
- Data Transformation: Prepares raw data for analysis.
- Cleaning Tasks: Handle missing values, duplicates, and outliers.
- Data Validation: Enforces rules for integrity.
- Data Profiling: Understand data characteristics.
- Tools: Use Pandas, PySpark, or dbt.
- Automation: Use Apache Airflow for workflows.
Challenge:
Can you build a data pipeline that ingests data from an API, cleans it, transforms it, performs data validation, and stores it in a database? Share your approach below! 🔥
Enjoyed this guide? Let us know how you're transforming and cleaning data in your projects! 🚀